
The promise of distributed systems
People often see distributed systems as the answer to today’s computing challenges. When a single machine can’t handle the load, you can spread work across several services, servers, or locations. This approach offers better scalability, higher availability, and more flexibility in building and running systems.
At first, this idea seems simple. If one part gets overloaded, just add more. If a service fails, let another step in. If traffic increases, scale out. From the outside, distributed systems look like a practical way to get past the limits of a single machine.
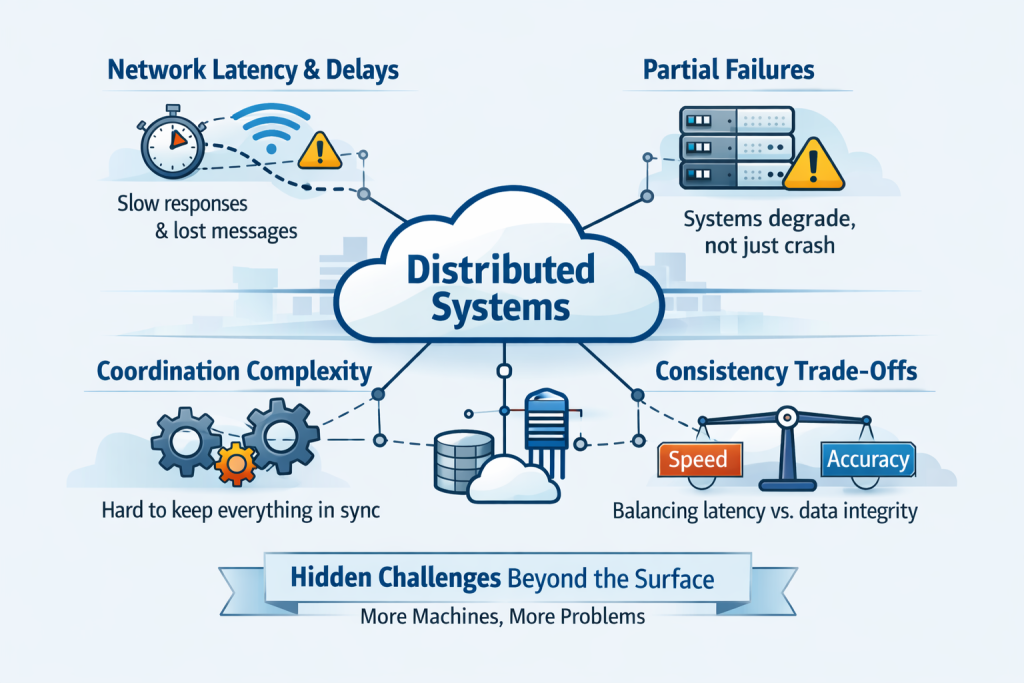
But this is where confusion often starts. Distributed systems aren’t hard just because they use more machines. The real challenge is that each extra machine adds distance, coordination needs, uncertainty, and new ways things can fail.
A single system is easier to reason about
A system on a single machine is already complex, but most of that complexity stays in one place. Memory is local, communication between parts is quick, and failures are easier to spot. Timing is more predictable, and there are fewer dependencies to track.
When a system becomes distributed, many old assumptions no longer hold. Communication isn’t local anymore. Messages might be delayed, requests can time out, and a service might look healthy even if one of its dependencies is failing quietly. Data might not be consistent when you read it from another node.
This means distributed systems are harder, not because engineers lose their skills, but because the environment becomes less predictable.One of the main differences between local and distributed systems is the network. In a single process, function calls are quick and reliable. Over a network, every interaction can be slowed down, lost, retried, or temporarily unavailable.
This affects how systems work in real life. What seems like a simple request between two services might actually involve steps like serialization, transport, routing, authentication, queueing, retries, and deserialization before anything useful happens. If this process slows down, everything that depends on it slows down too.
That’s why distributed systems make engineers pay close attention to something local systems often hide: communication isn’t free. Every remote call costs time, adds uncertainty, and can affect reliability.
Failure is no longer binary.
In simple systems, failure often feels black or white. A process either works or crashes. A server is either online or offline. But in distributed systems, failure is often only partial. completely fail. A database may accept writes but struggle with reads. A region may degrade rather than go down entirely. A message queue may keep operating while consumers fall behind. These are not clean failures. They are gray failures, and gray failures are much harder to detect and reason with. This is one of the toughest parts of distributed systems: the system might still be running but already becoming unhealthy. Users might notice things are slow, inconsistent, or see random errors. For engineers, it’s a diagnosis problem, not just a matter of restarting something. problem.
Coordination creates complexity
As soon as multiple parts of a system need to agree on something, things get much more complex. Services might have to coordinate on identity, state, order, locking, replication, elections, retries, or consistency rules. That coordination is rarely free. The more a distributed system depends on tight coordination, the more sensitive it becomes to delay and failure. Strong coordination can improve correctness, but it can also reduce performance and resilience if used carelessly.
This is why distributed systems often require trade-offs instead of simple solutions. Making a system more consistent might slow it down. Improving availability can make correctness harder. Boosting throughput might make debugging tougher.y is often treated like a performance concern, but in distributed systems, it is much more than that. Latency shapes architecture.
A slow dependency doesn’t stay a small problem for long. It affects request chains, queue sizes, retry patterns, timeout settings, and resource use. When many services depend on each other simultaneously, latency adds up. What seems fine in one service can become a big issue when it happens across many layers, which s why distributed systems become difficult at scale. Problems are not only caused by major outages. Small delays, small inefficiencies, and small dependencies can combine into larger instability over time.
In distributed systems, being slow is often just another kind of failure.
Consistency is a design choice, not a default.
Many people new to distributed systems think data should always look the same everywhere, right away. But in these systems, that expectation can be costly.ve.
Replication makes systems more available and resilient, but it also brings timing issues. Data written in one spot might not show up right away somewhere else. Systems have to choose when to focus on consistency, when to allow delays, and when it’s okay for things to match up later.
This is one reason it’s hard to talk simply about distributed systems. The question isn’t usually “What’s the right design?” It’s more often “What kind of correctness matters most for this system?”
A payment system, a chat app, and an analytics pipeline don’t all need the same consistency model. Treating them the same way leads to bad design.
Abstraction helps, but it can also hide too much.
Modern platforms make it easier to build distributed systems. Tools such as containers, orchestration, managed databases, service meshes, and cloud platforms help reduce the effort required to run them. These tools are helpful and often needed. Abstraction does not remove the complexity of distributed systems. It changes where the complexity is seen. Teams may not manage physical networking directly, but they still deal with network behavior. They may not operate databases from scratch, but they still depend on replication, failover, and consistency decisions. They may not provision every server manually, but they still inherit the behavior of a distributed platform.
The problem isn’t abstraction itself. The real risk is forgetting what’s hidden by those abstractions. Systems get harder to understand when they appear simple on the surface but remain complex and distributed beneath the surface.
Observability becomes essential
In local systems, you can often figure out what’s happening just by looking directly. In distributed systems, that’s rarely the case. One user request might go through many services, queues, caches, and databases before it’s done. Without good observability, engineers are left guessing.
That’s why logs, metrics, traces, and dependency maps are so important. They aren’t just nice extras for experienced teams. These tools make a distributed system easier to understand.
A system that cannot be observed. If you can’t clearly observe a system, it will eventually become hard to trust.
The real challenge with distributed systems isn’t that they’re advanced or hard to understand. It’s that they make engineers work in a world where delay, failure, inconsistency, and uncertainty are the norm, not the exception.
That changes the mindset required to build software. Engineers
They are no longer just writing logic. They are designing behavior across unreliable boundaries. They are deciding what to do when messages arrive late, when services disagree, when one part of the system is overloaded, or when failure is partial and recovery is incomplete.
This is why distributed systems are tough on assumptions. They reveal every spot where software quietly expected things to be immediate, certain, or perfectly coordinated.TED systems thinking looks like
Prefer simplicity where possible.
Not every problem needs a distributed solution. Sometimes the best design is the one that avoids extra service boundaries and keeps things simple.
Design for partial failure
Failures won’t always be clear-cut. Systems should be able to handle it smoothly when one part gets slow, goes down, or becomes inconsistent.
Be intentional about co.
Every network call adds cost and uncertainty. Treat remote interactions as important design choices, not just small technical details.tion details.
Choose trade-offs consciously
Consistency, availability, latency, and complexity often pull in different directions. Good design starts by knowing which trade-offs matter most for your system.
Invest in observability.
If a system is distributed, it should be observable from the start. Visibility isn’t something to add later—it’s part of the architecture from day one.structure itself.
Conclusion
Distributed systems are tougher than they seem because distribution changes what makes software hard. A system isn’t just about its internal logic anymore—it’s also about how it communicates, handles timing, coordinates, and deals with failures.
The real challenge isn’t just having more machines. It’s these machines that add uncertainty to every interaction. Latency shapes the system. Failures are often partial. Coordination gets costly. Abstraction helps, but it can also hide problems. That’s why distributed systems need careful thought. They’re powerful, but not simple by nature. The more they offer in scalability and resilience, the more they require disciplined design, good visibility, and smart trade-offs.